
Chapter 1. From AI to Agentic Applications
Systems Engineering for Agentic Applications

Read this chapter at Systems Engineering for Agentic Applications
This chapter covers
AI foundations
AI agents and agentic applications
First contact with AI APIs and AI agents
Every application will be an agentic application. From coding agents that run locally in your IDE or terminal to enterprise agents that orchestrate actions in distributed environments, an agentic application is an application that operates autonomously and continuously in pursuit of an objective (Figure 1.1).

Agentic applications are composed of AI agents and AI agents are composed of AI APIs. To engineer these systems effectively, we must understand their structure and behavior from the bottom up. In this chapter, we start on the lower levels to understand how tokens, models, training, and inference constrain what happens at higher levels.
1.1 AI Foundations
The transformation of traditional applications into agentic applications is powered by Large Language Models (LLMs). Unlike previous AI technologies that are narrow and domain-specific, LLMs are broad and general purpose, capable of reasoning about objectives and orchestrating complex actions. Consequently, throughout this book we will examine the world of AI APIs, agents, and agentic apps primarily through the lens of LLMs.
Conceptual Framework
While we use concrete examples from various AI providers, we focus on building a conceptual framework that captures the essential behavior shared across systems. The mechanics may differ, but the higher-level patterns remain consistent and provide reliable foundations for engineering agentic applications
LLMs are built from four fundamental components: tokens, models, training, and inference (see Figure 1.2).
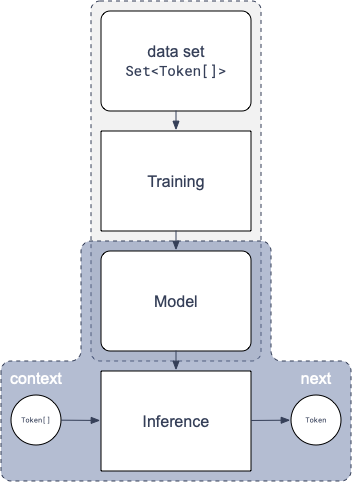
Systems engineers don't implement these low-level components, but understanding these foundations, even at a conceptual level, is essential for building reliable and scalable agentic applications.
1.1.1 Tokens
LLMs operate on text: They are trained on text, receive text as input, and return text as output. However, LLMs process text differently from humans. Humans delineate text into characters or into words (see Figure 1.3).

LLMs instead delineate text into tokens, that is, numerical identifiers for text fragments (see Figure 1.4).

Different tokenizers assign different numeric values to text fragments. For our purposes, we abstract tokenization to its essential interface (see Listing 1.1):
// A Token is a numerical representation of a fragment of text
type Token = number
interface Tokenizer {
// Abstract function to represent the translation of text into tokens
function encode(String) : Token[]
// Abstract function to represent the translation of tokens into text
function decode(Token[]) : String
}Listing 1.1: Abstract representation of a tokenizer as an interface with encode and decode functions
A tokenizer maintains a mapping from tokens to their associated text fragments. Additionally, it may define special tokens or control tokens (similar to control characters such as carriage return in ASCII or Unicode). The set of all tokens is also called the alphabet or vocabulary.
Read the rest of this chapter at Systems Engineering for Agentic Applications